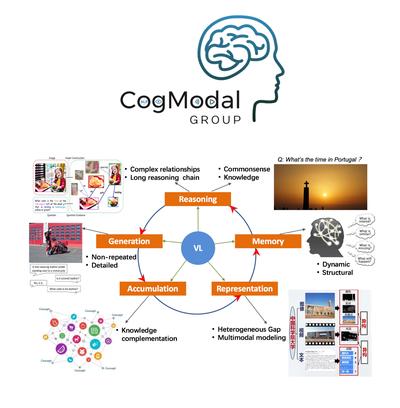
Welcome to CogModal Group! (Cognition-Inspired Cross-Modal Intelligence Group). A long-standing challenge of both cognitive science and artificial intelligence is understanding how humans manage to learn knowledge and solve problems from multi-modal information, e.g. text, image, video, and audio, with relatively little supervised instruction. Cognitive science explores empirical evidence to reveal why humans can understand the world and how they realize it. From the artificial intelligence view, our CogModal group has a great interest in developing human-like AI techniques from the implications of inherent mechanisms in cognitive science. To this end, our members mainly focus on five research topics that correspond to human basic abilities in multi-modal information cognition: multi-modal information Representation, Memory, Reasoning, Generation, and Accumulation. These research topics cover a wide range of tasks and applications including Cross-modal Information Retrieval, Referring Expression, Visual Question Answering, Image/Video Captioning, Text-based Image Generation and Vision-Language Navigation etc.
🌟 You are the th visitor of our group!
Join us!
🌟 Email: yujing02 at iie dot ac dot cn
🌟 Zhihu link: Cognition-Inspired Cross-Modal Intelligent Articles
News
{kind=link}
{kind=link}
- Jing Yu gave an invited online talk “ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification” in the Information Engineering University. The slides are available here.
- Yang Ding, Jing Yu(corresponding author), Bang Liu, Yue Hu, Mingxin Cui, Qi Wu. MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering,CVPR, 2022.
- ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification * WWW videos
- WLinker: Modeling Relational Triplet Extraction as Word Linking
- APER: AdaPtive Evidence-driven Reasoning Network for machine reading comprehension with unanswerable questions.
- Impact factor: 5.921 !
- Evolving Attention with Residual Convolutions
- CogTree: Cognition Tree Loss for Unbiased Scene Graph Generation
- Jing Yu gave an invited talk “Towards Cognition-Inspired Vision and Language Methods”in the CCF YOCSEF Xi`an Forum “How does Vision and Language 1+1>2?”
- The slides are available here.
- Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees.
- DMRFNet: Deep Multimodal Reasoning and Fusion for Visual Question Answering and explanation generation.
- Impact factor: 12.975 !
- MCR-NET: A Multi-Step Co-Interactive Relation Network for Unanswerable Questions on Machine Reading Comprehension.
- Jing Yu will give a talk of “Deep Reasoning for Visual Question Answering” in Shanghai University & online. The talk is on 15/10/2020, 10:00~12:00 a.m., UTC+8.
- More information about the talk is avaible here.
- Learning Dual Encoding Model for Adaptive Visual Understanding in Visual Dialogue.
- Impact factor: 9.34 !
- KBGN: Knowledge-Bridge Graph Network for Adaptive Vision-Text Reasoning in Visual Dialogue.
- Learning cross-modal correlations by exploring inter-word semantics and stacked co-attention.
- Cross-modal knowledge reasoning for knowledge-based visual question answering.
- Impact factor: 7.196 !
- Cross-modal learning with prior visual relation knowledge.
- Impact factor: 5.921 !
- Prior Visual Relationship For Visual Question Answering.
- Jing Yu gave an invited talk of “Deep Learning based Visual Question Answering” in Shanghai University, Shanghai, China.
- The slides are available here.
-
Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering. 代码链接
-
DAM: Deliberation, Abandon and Memory Networks for Generating Detailed and Non-repetitive Responses in Visual Dialogue.
-
accept rate: 592/4717 = 12.6%
- Multimodal feature fusion by relational reasoning and attention for visual question answering
- Impact factor: 12.975
- Reasoning on the Relation: Enhancing Visual Representation for Visual Question Answering and Cross-modal Retrieval
- Impact factor: 6.051
- Deep Visual Understanding Like Humans: An Adaptive Dual Encoding Model for Visual Dialogue.
- Unsupervised Learning of Deterministic Dialogue Structure with Edge-Enhanced Graph Auto-Encoder
- Semantic Modeling of Textual Relationships in Cross-modal Retrieval.